Kubelet Architecture
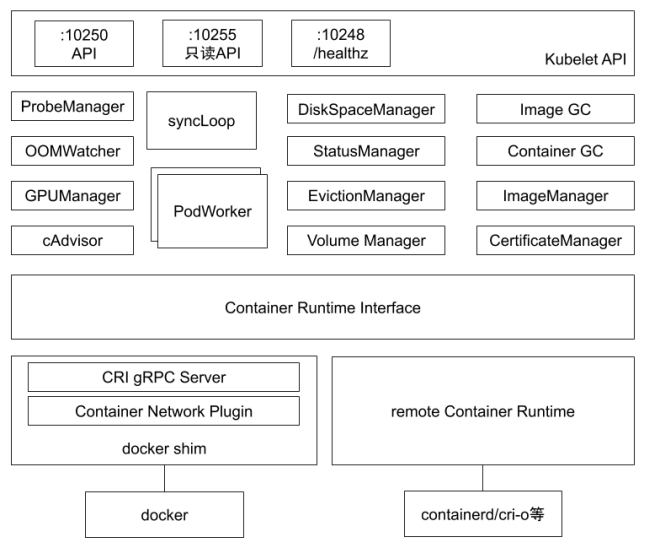
As shown in the kubelet internal component structure diagram below, Kubelet is composed of many internal components:
- Kubelet API: Including the authenticated API on port 10250, cAdvisor API on port 4194, read-only API on port 10255, and health check API on port 10248.
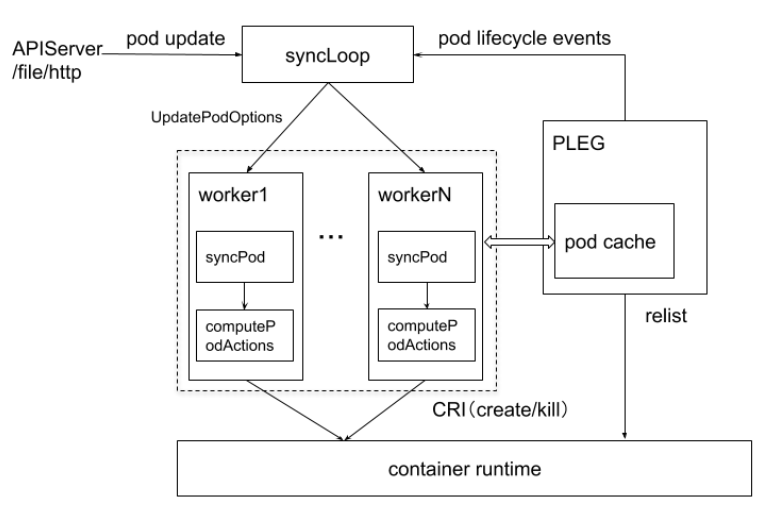
- syncLoop: Receives Pod updates from the API or manifest directories, sends them to podWorkers for processing, extensively using channels for async request handling.
- Auxiliary managers: Such as cAdvisor, PLEG, Volume Manager, etc., handling work outside of syncLoop.
- CRI: Container Runtime Interface, responsible for communicating with container runtime shims.
- Container runtimes: Such as dockershim, rkt, etc.
- Network plugins: Currently supports CNI and kubenet.
Kubelet Core Pod Management Flow
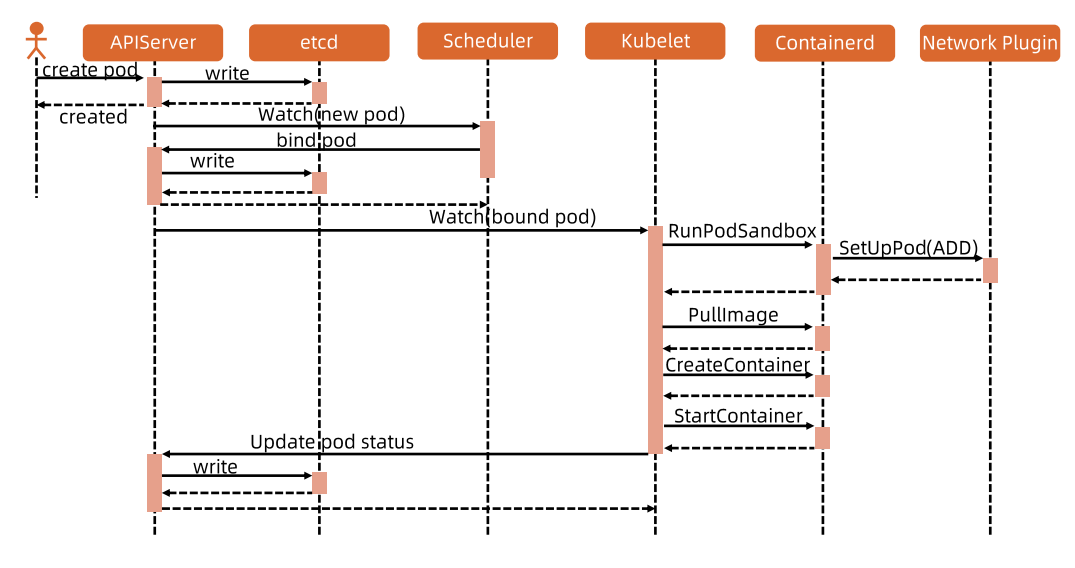
Each node runs a kubelet service process, listening on port 10250 by default.
- Receives and executes instructions from the master
- Manages Pods and containers within Pods
- Each kubelet process registers its node information on the API Server, periodically reports resource usage to the master, and monitors node and container resources through cAdvisor.
Node Management
Node management primarily involves node self-registration and node status updates:
- kubelet can determine whether to register itself with the API Server via the –register-node startup parameter.
- If kubelet doesn’t use self-registration mode, users need to manually configure Node resource information and inform kubelet of the API Server’s location.
- At startup, kubelet registers node information via the API Server and periodically sends node updates. The API Server writes this information to etcd.
Pod Management
Getting the Pod List
Kubelet works with PodSpecs — YAML or JSON objects describing a Pod. Kubelet takes PodSpecs provided through various mechanisms (primarily through the apiserver) and ensures the Pods described in those PodSpecs are running and healthy.
Methods for providing the Pod list to Kubelet:
- File: Files in the config directory specified by –config (default /etc/kubernetes/manifests/). Rechecked every 20 seconds (configurable).
- HTTP endpoint (URL): Set via –manifest-url. Checked every 20 seconds (configurable).
- API Server: Watches the etcd directory via API Server, syncing the Pod list.
- HTTP server: Kubelet listens for HTTP requests and responds to simple APIs for submitting new Pod lists.
Getting Pod List and Creating Pods via API Server
Kubelet uses the API Server Client (created at kubelet startup) with Watch and List to monitor /registry/nodes/$current-node-name and /registry/pods directories, syncing information to the local cache.
Kubelet watches etcd — all Pod operations are captured by Kubelet. If a new Pod is bound to this node, it creates the Pod per the Pod list requirements.
If a local Pod is modified, Kubelet makes corresponding changes — for example, deleting a container within a Pod via Docker Client. If a Pod on this node is deleted, it deletes the corresponding Pod and its containers via Docker Client.
When Kubelet reads creation or modification tasks, it processes them as follows:
- Creates a data directory for the Pod.
- Reads the Pod list from the API Server.
- Mounts external Volumes for the Pod.
- Downloads Secrets used by the Pod.
- Checks Pods already running on the node. If the Pod has no containers or the Pause container hasn’t started, stops all container processes in the Pod. Deletes containers that need to be removed.
- Creates a container for each Pod using the
kubernetes/pauseimage. The Pause container takes over networking for all other containers in the Pod. For each new Pod, Kubelet first creates a Pause container, then creates the other containers. - For each container in the Pod:
- Computes a hash value, then queries Docker for the container’s hash by name. If found with a different hash, stops the Docker container and its associated Pause container. If identical, does nothing.
- If the container was terminated and has no specified restartPolicy, does nothing.
- Calls Docker Client to download the container image and run the container.
Static Pod
All Pods created through non-API-Server methods are called Static Pods. Kubelet reports Static Pod status to the API Server, which creates a matching Mirror Pod. The Mirror Pod’s status reflects the Static Pod’s actual status. When a Static Pod is deleted, its corresponding Mirror Pod is also deleted.
Container Health Checks
Pods check container health through two types of probes:
- (1) LivenessProbe: Determines if a container is healthy, telling Kubelet when a container is in an unhealthy state. If LivenessProbe detects an unhealthy container, Kubelet deletes it and handles it according to the container’s restart policy. If a container doesn’t include a LivenessProbe, Kubelet considers its LivenessProbe value to always be
Success. - (2) ReadinessProbe: Determines if a container has started and is ready to receive requests. If ReadinessProbe detects failure, the Pod’s status is modified. The Endpoint Controller removes the Endpoint entry containing the Pod’s IP from the Service’s Endpoints.
Kubelet periodically calls LivenessProbe to diagnose container health. LivenessProbe has three implementations:
- ExecAction: Executes a command inside the container. If the exit code is 0, the container is healthy.
- TCPSocketAction: Performs a TCP check via the container’s IP and port. If the port is accessible, the container is healthy.
- HTTPGetAction: Calls HTTP GET via the container’s IP, port, and path. If the response status code is >= 200 and < 400, the container is healthy.
cAdvisor Resource Monitoring
In Kubernetes clusters, application performance can be monitored at different levels: containers, Pods, Services, and the entire cluster. The Heapster project provides a basic monitoring platform — a cluster-level monitoring and event data Aggregator. Heapster runs as a Pod, discovers all running nodes through Kubelet, and checks resource usage. Kubelet obtains node and container data through cAdvisor. Heapster groups this information by Pod with associated labels, then pushes data to configurable backends for storage and visualization, including InfluxDB (with Grafana) and Google Cloud Monitoring.
cAdvisor is an open-source agent for analyzing container resource usage and performance characteristics, integrated into Kubelet. It starts with Kubelet and monitors a single node. cAdvisor automatically discovers all containers on its node and collects CPU, memory, filesystem, and network usage statistics.
cAdvisor exposes a simple UI on port 4194.
Kubelet Eviction
Kubelet monitors resource usage and uses eviction mechanisms to prevent compute and storage resource exhaustion. During eviction, Kubelet stops all containers in the Pod and sets PodPhase to Failed.
Kubelet periodically (housekeeping-interval) checks whether system resources have reached pre-configured eviction thresholds:
| Eviction Signal | Condition | Description |
|---|---|---|
| memory.available | MemoryPressure | memory.available := node.status.capacity[memory] - node.stats.memory.workingSet |
| nodefs.available | DiskPressure | nodefs.available := node.stats.fs.available |
| nodefs.inodesFree | DiskPressure | nodefs.inodesFree := node.stats.fs.inodesFree |
| imagefs.available | DiskPressure | imagefs.available := node.stats.runtime.imagefs.available |
| imagefs.inodesFree | DiskPressure | imagefs.inodesFree := node.stats.runtime.imagefs.inodesFree |
Eviction signals can be divided into soft and hard eviction:
- Soft Eviction: Used with eviction grace periods (eviction-soft-grace-period and eviction-max-pod-grace-period). Eviction only occurs after the grace period expires when the soft threshold is reached.
- Hard Eviction: Eviction executes immediately when the hard threshold is reached.
Eviction actions include reclaiming node resources and evicting user Pods:
- Reclaiming node resources
- When imagefs threshold is configured:
- nodefs threshold reached: Delete stopped Pods
- imagefs threshold reached: Delete unused images
- When imagefs threshold is not configured:
- nodefs threshold reached: Clean resources by deleting stopped Pods, then unused images
- When imagefs threshold is configured:
- Evicting user Pods
- Eviction order: BestEffort, Burstable, Guaranteed
- When imagefs threshold is configured:
- nodefs threshold reached: Evict based on nodefs usage (local volume + logs)
- imagefs threshold reached: Evict based on imagefs usage (container writable layer)
- When imagefs threshold is not configured:
- nodefs threshold reached: Evict based on total disk usage (local volume + logs + container writable layer)
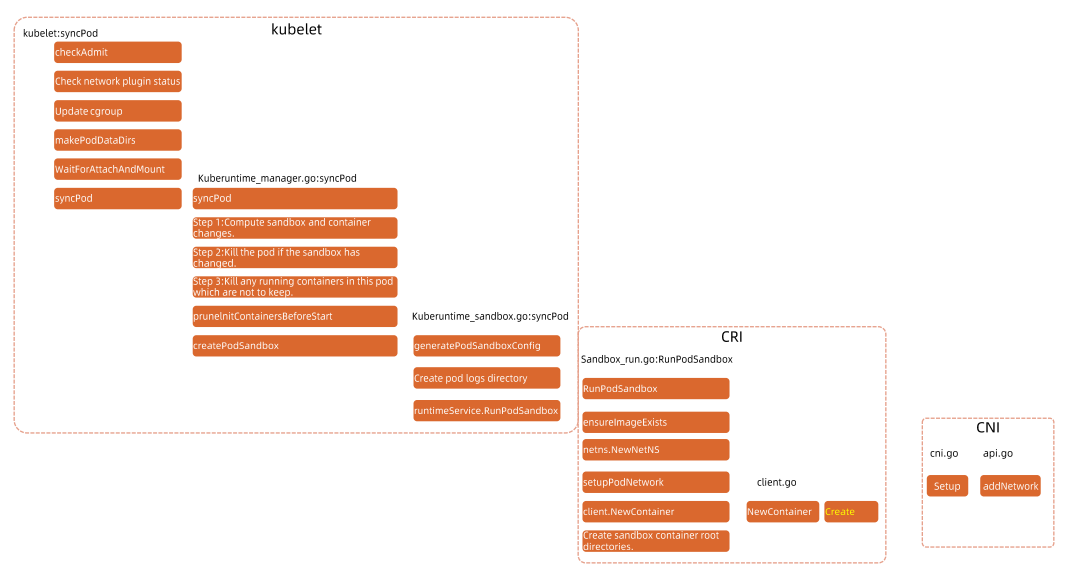
Pod Startup Flow
Kubelet Pod Startup Flow
Conclusion
Kubelet appears to be the most important component on the Worker Node. I didn’t expect a single kubelet to handle so much! Did you learn something new too?
Feel free to leave a comment on my blog. Your feedback motivates me to keep writing. Thank you for reading, and let’s grow together to become better versions of ourselves.
