Scheduler 嚴格算起來,算是特殊的 Controller,工作原理與其他控制器無差別。
Scheduler 的特殊職責在於監控當前集群所有未調度的 Pod,並且獲取當前集群的所有節點健康狀況和資源使用情控,為待調度的 Pod 選擇最佳節點,完成調度。
kube-scheduler 負責分配調度 Pod 到集群內的節點上,他監聽 kube-apiserver ,查詢還未分配 Node 的 Pod ,然後根據調度策略為這些 Pod 分配節點 (更新 Pod 的 NodeName Field)。
設計 scheduler 需要要充分考慮諸多因素:
- 公平調度
- 資源高效利用
- QoS(Quality of Service)
- affinity 和 antiaffinity
- 數據本地化 (data locality)
- 內部負載干擾 (inter-workload interference)
- deadlines
Scheduler
kube-scheduler 調度分為幾個階段:
- predicate: 將所有節點拿出來,過濾不符合條件節點。
- priority: 優先級排序,選擇優先級最高的節點。
- Bind : 將計算節點與 Pod 綁定,完成調度。
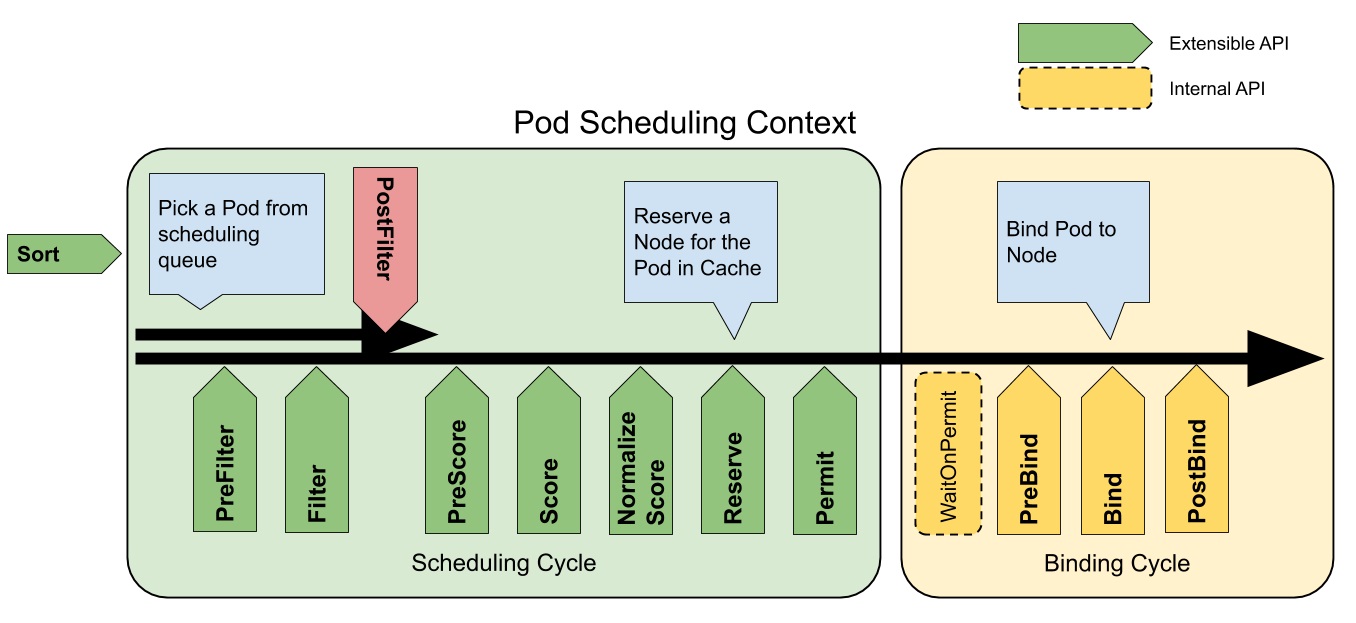
Scheduling Cycle & Binding Cycle
Predicate 策略
這邊只有列出常見的策略,還有其他很多策略,你也可以編寫自己的策略。
- PodFitsHostPorts: 檢查是否有 Host Ports 衝突。
- PodFitsPorts: 同PodFitsHostPorts。
- PodFitsResources: 檢查 Node 的資源是否充足,包括允許的 Pod 數量、CPU、內存、GPU 個數以及其他的 OpaqueIntResources。
- Hostname: 檢查 pod.Spec.NodeName 是否與候選節點一致。
- MatchNodeSelector: 檢查候選節點的 pod.Spec.NodeSelector 是否匹配。
- NoVolumeZoneConflict: 檢查 volume zone 是否衝突。
- MatchInterPodAffinity: 檢查是否匹配 Pod 的 affinity 要求。
- NoDiskConflict: 檢查是否存在 Volume 衝突,僅用於 GCP PD 、 AWS EBS 、 Ceph RBD 以及 iSCSI 。
- PodToleratesNodeTaints: 檢查 Pod 是否容忍 Node Taints。
- CheckNodeMemoryPressure: 檢查 Pod 是否可以調度到 MemoryPressure 的節點上。
- CheckNodeDiskPressure: 檢查 Pod 是否可以調度到 DiskPressure 的節點上。
- NoVolumeNodeConflict: 檢查節點是否滿足 Pod 所引用的 Volume 的條件。
Priorites 策略
經過 Predicate 之後,就要去為剩下的機器打分數,然後排序。
- SelectorSpreadPriority: 優先減少節點上屬於同一個 Service 或 Replication Controller 的 Pod 數量。
- InterPodAffinityPriority: 優先將 Pod 調度到相同的拓樸上 (如同一個節點、Rack、Zone 等)。
- LeastRequestedPriority: 優先調度到請求資源少的節點上。
- BalancedResourceAllocation: 優先平衡各節點的資源使用。
- NodePreferAvoidPodsPriority: alpha.kubernetes.io/perferAvoidPods 字段判斷,權重為 10000 ,避免其他優先即策略的影響。
- NodeAffinitypriority: 優先調度到匹配 NodeAffinity 的節點上。
- TaintTolerationPriority: 優先調度到匹配 TaintToleration 節點上。
- ServiceSpreadingPriority: 盡量將同一個 service 的 Pod 分配到不同節點上,已經被 SelectorSpreadPriority 替代 (默認未使用)。
- EqualPriority: 將所有節點的優先級設置為1 (默認未使用)。
- ImageLocalityPriority: 盡量將使用大 Image 的容器調度到已經下拉的該 Image 的節點上 (默認未使用)。
- MostRequestedPriority: 盡量調度到已經使用過的 Node 上,特別適用於 cluster0autoscaler (默認未使用)。
指定 Node 調度
可以通過 nodeSelector 、 nodeAffinity 、 podAffinity 以及 Taints 與 tolerations 等來將 Pod 調度到需要的 Node 上。
也可以指定設置 nodeName 參數,將 Pod 調度到指定 Node 節點上。
NodeSelector
可以在 pod 上面標記 nodeSelector ,讓在創建 pod 的時候調度到打有對應的 key 與 value 的機器上。
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
disktype: ssd
NodeAffinity
NodeAffinity 目前支援兩種
- requiredDuringSchedulingIgnoredDuringExecution: 必須滿足條件。
- preferedDuringSchedulingIgnoredDuringExecution: 優選條件。
apiVersion: v1
kind: Pod
metadata:
name: with-affinity-anti-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: label-1
operator: In
values:
- key-1
- weight: 50
preference:
matchExpressions:
- key: label-2
operator: In
values:
- key-2
containers:
- name: with-node-affinity
image: k8s.gcr.io/pause:2.0
PodAffinity
PodAffinity 基於 Pod 的標籤來選擇 Node,僅調度滿足條件 Pod 所在的 Node 上,支持 PodAffinity 和 PodAntiffinity。
- requiredDuringSchedulingIgnoredDuringExecution: 必須滿足條件。
- preferedDuringSchedulingIgnoredDuringExecution: 優選條件。
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: topology.kubernetes.io/hostname
containers:
- name: with-pod-affinity
image: k8s.gcr.io/pause:2.0
Taints 和 Tolerations
在使用 NodeSelector 的場景下,是不會強制可以拒絕 Pod 調度到某些 Node 上的,或者是在初步規劃 kubernetes 時,沒有考慮到會有所有部門都會使用 Kubernetes 的技術,結果後面大家都上 k8s 導致需要為某些節點做牆隔離,為了解決這些問題,所以可以使用 Taints 和 Tolerations。
Taint 和 Tolerations 用於保證 Pod 不會被調度到不合適的 Node 上,其中 Taint 應用於 Node 上,而 Toleration 則應用在 Pod 上。
目前支持的 Taint 類型:
- NoSchedule: 新的 Pod 不會被調度到該節點上,不影響正在運行的 Pod。
- PreferNoSchedule: Soft 版的 NoSchedule ,盡量不調度到該 Node 上。
- NoExecute: 新的 Pod 不調度到該 Node 上,並且刪除 (evict) 已經在運行的 Pod。Pod 可以增加一個時間 (tolerationSecondes)。
然而,當 Pod 與 Toleration 匹配 Node 的所有 Taints 的時候,可以調度到該 Node 上,當 Pod 是已經運行的時候,也不會被刪除 (evicted)。
在 kubernets 內,當一個節點有問題的時候,他也是通過 taints 的機制,將機器打上 key value,以確保不會在有 pod 不會再被調度上去,並且打上 tolerationSecondes 確保在一訂時間內恢復的話, pod 是不會被驅逐的。
PriorityClass
從 v1.8 開始,kube-scheduler 支持定義 Pod 的優先級,從而保證高優先級的 Pod 優先調度。
preemptionPolicy:
- PreemptLowerPriority: 將允許該 PriorityClass 的 Pod 搶占較低優先級的 Pod 。
- Never: 非搶佔式。
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
preemptionPolicy: Never
globalDefault: false
description: "This priority class should be used for XYZ service pods only."
多調度器
如果默認的調度器不滿足需求,還可以部屬自定義的調度器。並且在整個集群中,同時可以運行多個調度器實例,通過 pod.spec.schedulerName 來選擇使用哪一個調度器 (默認使用內置的調度器)。
總結
對於 k8s 整體運作原理已經開始有更深入的認識了,期待自己早日搞懂 k8s 。
歡迎到我的 Facebook Alan 的筆記本 留言,順手給我個讚吧!你的讚將成為我持續更新的動力,感謝你的閱讀,讓我們一起學習成為更好的自己。
