I’ve been studying Kubernetes recently, so I need to become good friends with the Go language. While reading, I came across goroutines, but couldn’t fully understand where they came from and why they exist. So before we dive deep into goroutines, we should first learn some history — this will give us a more comprehensive understanding of the principles and design philosophy behind goroutines.
The Origin of Golang’s Scheduler
The Single-Process Era
We know that software runs on top of the operating system, and the CPU does the actual computation. In early operating systems, each program was a process, and the next process could only run after the current one finished.
Suppose there are three processes: A, B, and C. The CPU would schedule them sequentially in order of execution.
Example: A -> B -> C
However, the single-process operating system era faced these problems:
- Only one process could run at a time — the computer could only execute tasks one by one.
- If a process encountered a blocking I/O operation, it caused CPU resource waste.
This gave rise to multi-process / multi-thread operating systems.
The Multi-Process / Multi-Thread Era
In multi-process / multi-thread operating systems, the blocking problem was solved because the CPU could immediately switch to another process when one was blocked. The CPU scheduling algorithm ensured that running processes were allocated CPU time slices. From a macroscopic perspective, multiple processes appeared to run simultaneously. If you’re unfamiliar with CPU scheduling principles, check out CPU Scheduling Principles.
When multiple processes share CPU time slices, everything seems fine. But engineers discovered new problems: creating, switching, and destroying processes all take considerable time. While CPU utilization improved, when there were too many processes, a large portion of CPU time was spent on context switching.
So what overhead does process switching incur?
Process Switching Overhead
- Direct costs
- Switching the Page Global Directory (PGD)
- Switching the kernel stack
- Switching hardware context (data that must be loaded into registers before a process can resume, collectively called hardware context)
- Flushing the TLB
- Executing the system scheduler code
- Indirect costs
- CPU cache invalidation leads to more memory I/O operations for direct access
So how can we improve CPU utilization?
Coroutines to Improve CPU Utilization
Clever engineers discovered that threads are divided into kernel threads (Kernel Thread) and user threads (User Thread). A “user thread” must be bound to a “kernel thread,” but the CPU doesn’t know about “user threads” — it only knows it’s running a “kernel thread” (Linux PCB process control block).
So can we create and maintain lightweight coroutines in user space, binding multiple lightweight threads to the same kernel thread? If a kernel thread gets a time slice, couldn’t we execute all the user-space coroutines within that time? Then hand the CPU back. Wouldn’t this significantly improve overall execution efficiency?
This is the principle behind Go’s thread scheduling. Let’s take a look at Goroutines.
Goroutine
Goroutine is Go’s implementation of coroutines. Go implements user-space threads based on the GMP model:
- Goroutine (G): Represents a goroutine. Each goroutine has its own stack space and timer. The initial stack size is around 2KB and grows as needed.
- Machine (M): An abstraction representing a kernel thread. Records kernel thread stack information. When a goroutine is scheduled to a thread, it uses the goroutine’s own stack information.
- Processor (P): Represents the scheduler. Responsible for scheduling goroutines, maintaining a local goroutine queue, and binding the queue to an M. M retrieves goroutines from P and executes them. P is also responsible for some memory management.
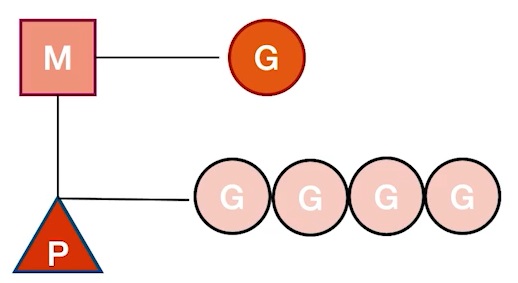
MPG Relationships
- KSE: Kernel Scheduling Entity
- M has a one-to-one correspondence with Kernel Tasks.
- A single P can have multiple Gs. P determines which M to bind to based on the current state. For example, if an M has entered kernel mode, P may switch to find another idle M to execute on.
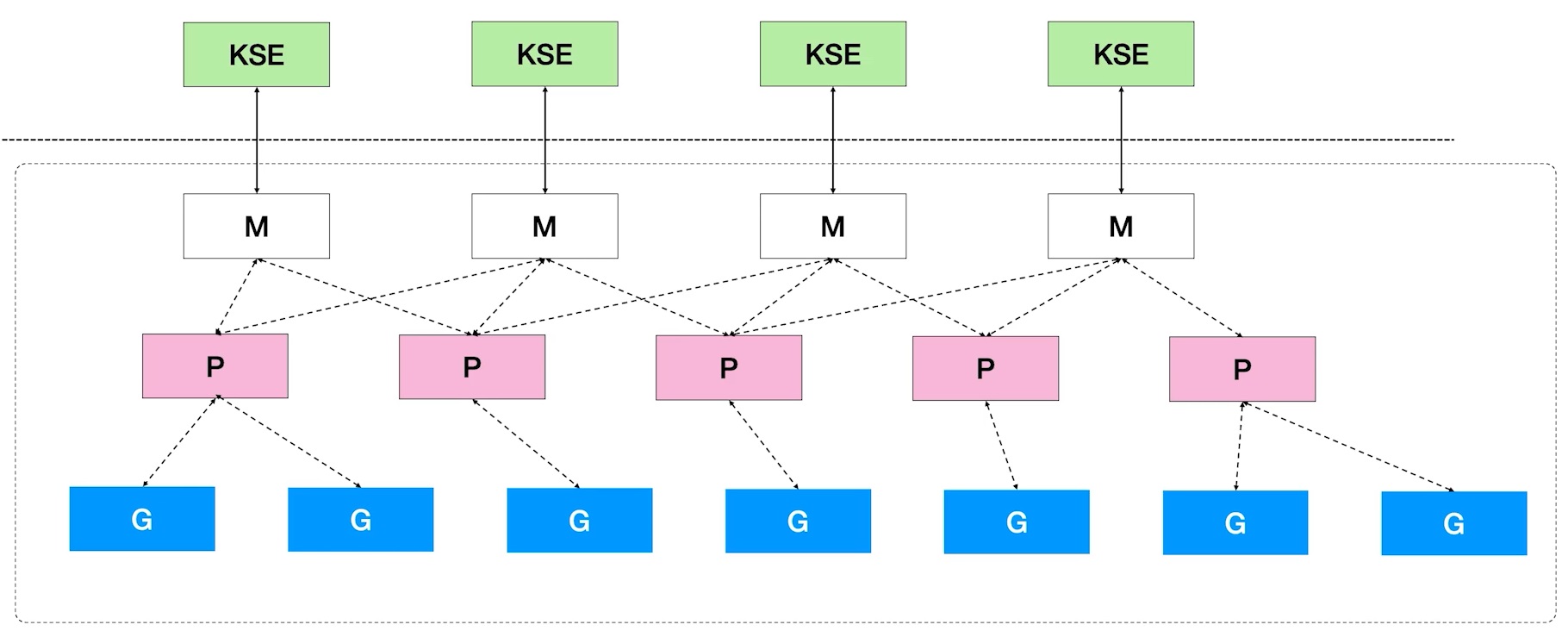
GMP Model Details
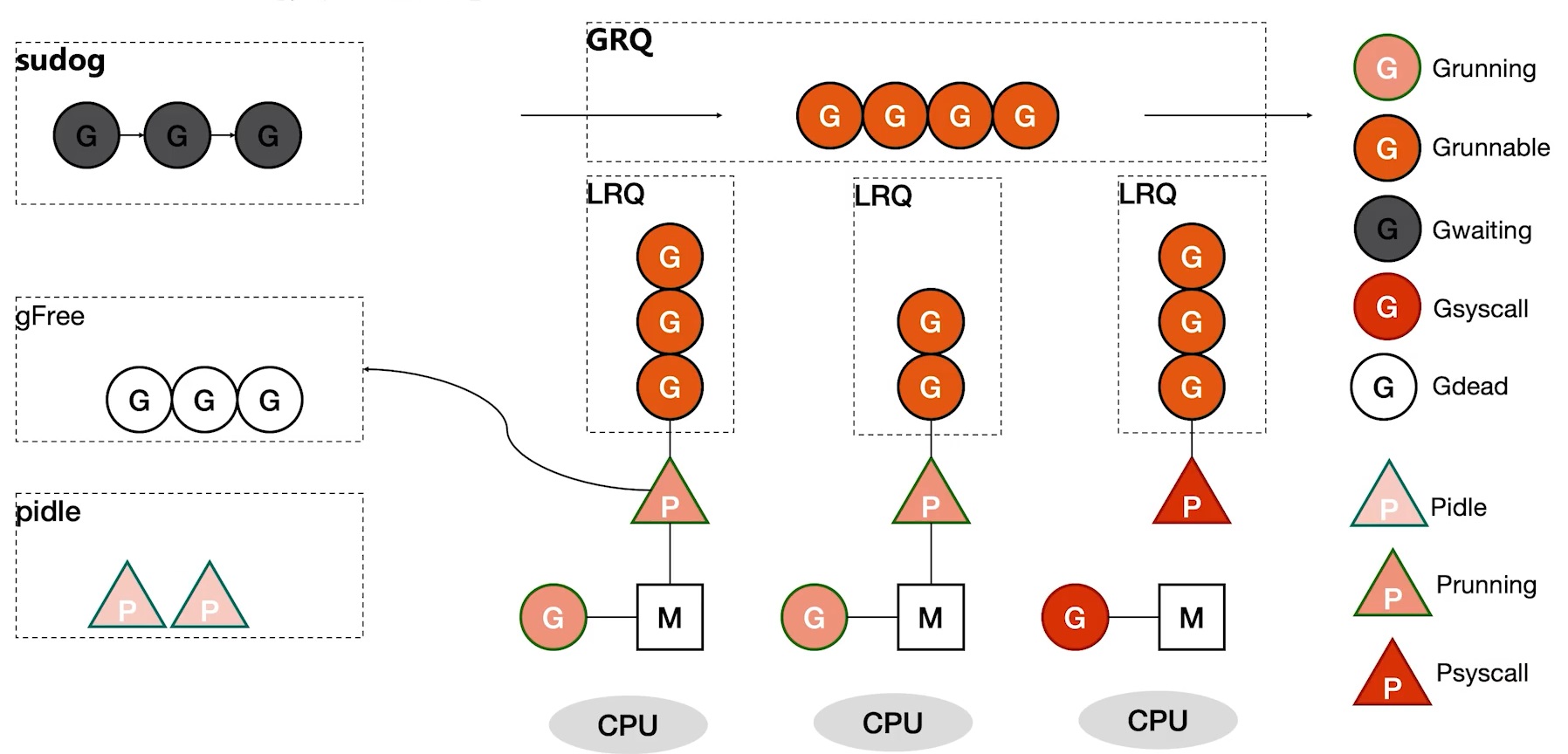
- LRQ: Local Run Queue
- GRQ: Global Run Queue
- sudog: Blocking queue
- gFree: Global free G list
- pidle: Global idle P list
Here are some details about the diagram above:
- When a Go program starts and spawns multiple goroutines, there’s a configurable parameter for how many concurrent threads Go can run. Typically, this matches the number of CPUs on your machine. During initialization, P instances are created according to this setting.
- When Go starts executing, the main function itself is also a goroutine, so it gets placed on a P. If the main function spawns many goroutines, they queue up on the current P. At this point, the multi-core advantage isn’t fully utilized because all Gs are mounted on the same P. But other Ps won’t just sit idle — that would waste CPU!
- If a P has no work, it checks the GRQ. If there’s still nothing, it looks at other Ps to see if they have Gs to execute. If it finds the first P has queued Gs, it steals half. Since all Ps have this mechanism, the backlog of Gs is quickly consumed.
- What if we create more Gs than the LRQ can hold (default 256)? The overflow goes to the GRQ.
- If an M enters kernel mode, P unbinds from it and looks for another idle M to bind with.
- If a G becomes blocked, the waiting G gets placed in the sudog blocking queue with no P binding.
- After a G finishes running, it places itself in gFree for reuse, reducing overhead.
P States
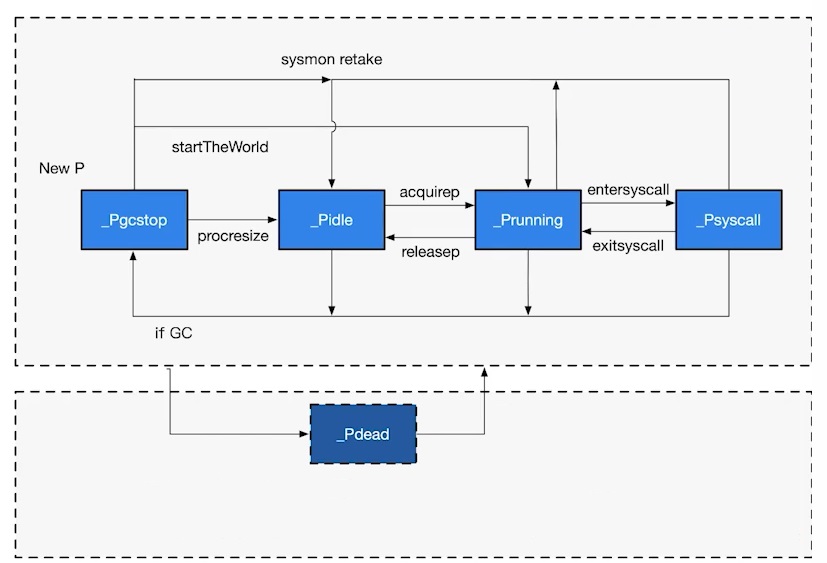
- _Pidle: The processor is not running user code or the scheduler. Held by the idle queue or a structure changing its state. The run queue is empty.
- _Prunning: Held by thread M, currently executing user code or the scheduler.
- _Psyscall: Not executing user code. The current thread is trapped in a system call.
- _Pgcstop: Held by thread M. The current processor is stopped for garbage collection.
- _Pdead: The current processor is no longer in use.
G States
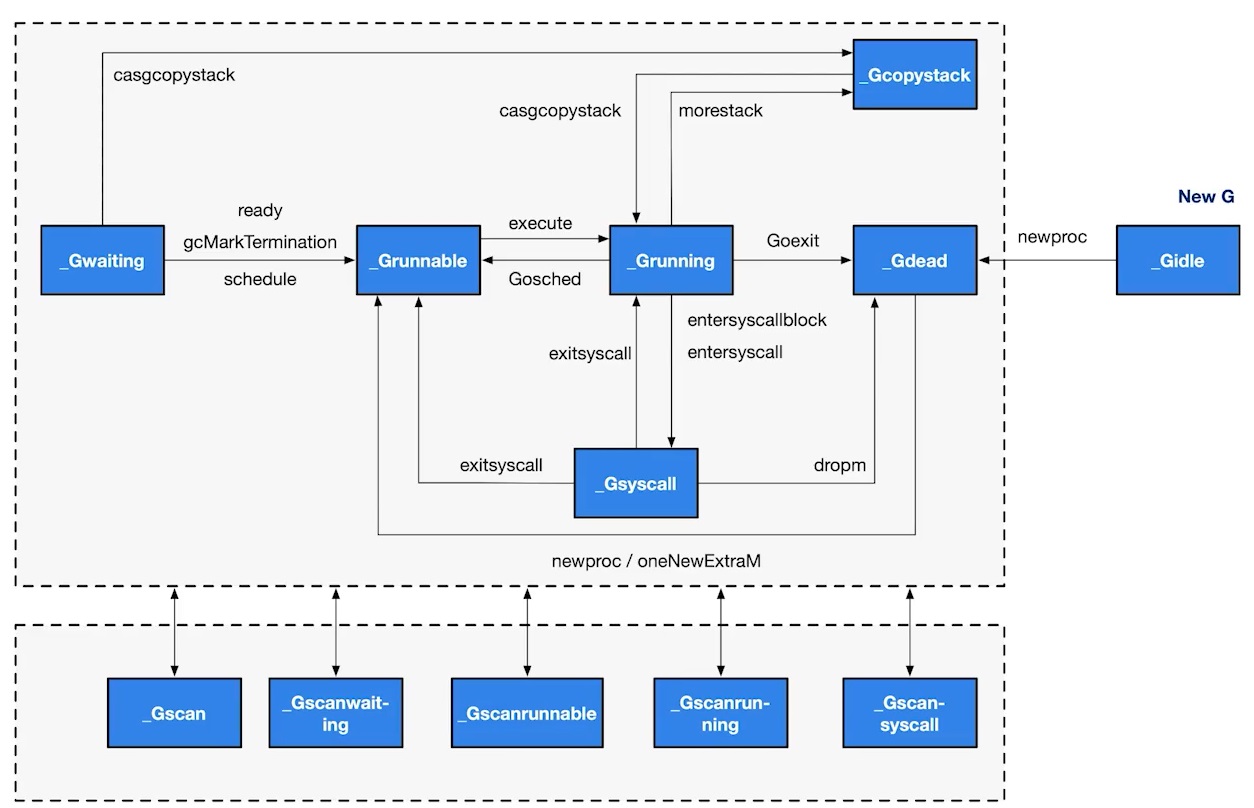
- _Gidle: Just allocated and not yet initialized. Value is 0, the default after creating a goroutine.
- _Grunnable: Not executing code, no stack ownership. Stored in a run queue — possibly in a P’s local queue or the global queue.
- _Grunning: Currently executing code. Owns the stack.
- _Gsyscall: Executing a system call. Owns the stack, detached from P but bound to a specific M. Will be assigned to a run queue after the call ends.
- _Gwaiting: A blocked goroutine, blocked on a channel send or receive queue.
- _Gdead: Currently unused, not executing code. May have an allocated stack. Found in the free list — could be a freshly initialized goroutine or one that exited via goexit.
- _Gcopystack: Stack is being copied. Not executing code, not in a run queue.
- _Gscan: GC is scanning the stack space. Not executing code. Can coexist with other states.
Scheduler Behavior
- To ensure fairness, when there are pending Gs in the GRQ, schedtick ensures a certain probability (1/61) of fetching G from the GRQ.
- Look for pending G in P’s LRQ.
- If neither of the above finds a G, runtime.findrunnable performs a blocking search:
- Search the LRQ and GRQ.
- Check the network poller for Gs waiting to run.
- Use runtime.runqsteal to try stealing half the Gs from another random P.
Conclusion
It’s been a while since I studied such hardcore knowledge. I feel like I might not fully digest it today — I’ll need to review it several more times. What are your thoughts after reading this?
Feel free to leave a comment on my blog. Your feedback motivates me to keep writing. Thank you for reading, and let’s grow together to become better versions of ourselves.
References
Errata
Thanks to Wang Zhi for finding some errors in this article. The corrections have been made.
