In any system, what is the most important thing? The answer is simple: data. So I’m starting my deep dive with Kubernetes’ database — etcd!
What is etcd?
etcd is a distributed key-value store developed by CoreOS based on the Raft algorithm. It can be used for service discovery, shared configuration, and consistency guarantees (such as database leader election, distributed locks, etc.).
In distributed systems, managing state across nodes has always been challenging. etcd is designed specifically for service discovery and registration in cluster environments. It provides features like data TTL expiration, data change monitoring, multi-value operations, directory watching, distributed lock atomic operations, and more — making it easy to track and manage cluster node states.
etcd Characteristics
- Simple: User-facing API accessible via curl.
- Secure: Optional SSL client certificate authentication.
- Fast: 1,000 writes per second and 2,000+ reads per second on a single instance.
- Reliable: Uses the Raft algorithm to ensure consistency.
etcd Terminology
- Raft: A strong consistency algorithm.
- Node: An instance of a Raft State Machine.
- Member: An etcd instance that manages a Node and can serve client requests.
- Peer: A reference to another Member in the same etcd cluster.
- WAL: Write-Ahead Log, the log format etcd uses for persistent storage.
- Snapshot: A snapshot etcd uses to prevent excessive WAL files, storing the etcd data state.
- Proxy: An etcd mode that provides reverse proxy services for the etcd cluster.
- Leader: The node elected through Raft consensus that handles all data submissions.
- Follower: Nodes that lost the election serve as subordinate nodes in Raft, providing strong consistency guarantees.
- Candidate: When a Follower doesn’t receive the Leader’s heartbeat for a certain period, it transitions to Candidate and initiates a new election.
- Term: The period from when a node becomes Leader to the next election, similar to a term of office.
- Index: A data sequence number. Raft uses Term and Index to locate data.
etcd Use Cases
Key-Value Storage
etcd is a key-value based data store. All other applications are extensions built on top of the key-value functionality.
- Key-value format storage is generally much faster than relational databases.
- Supports both dynamic storage (RAM) and static storage (Disk).
- Distributed storage that can form multi-node clusters.
- Storage structure is similar to a directory tree (B+ tree).
Service Registration and Discovery
- A strongly consistent, highly available service storage directory.
- etcd, based on the Raft algorithm, is inherently a strongly consistent, highly available service storage directory.
- A mechanism for registering services and monitoring service health.
- Users can register services in etcd and configure key TTLs for registered services, maintaining service heartbeats to monitor health status.
Message Publishing and Subscription
- In distributed systems, message publishing and subscription is one of the most suitable communication methods between components.
- Build a shared configuration center where data providers publish messages and consumers subscribe to topics of interest. Once a topic has new messages, subscribers are notified immediately.
- This approach enables centralized management and dynamic updates of distributed system configurations.
- Application configuration information is stored in etcd for centralized management.
- Applications actively fetch configuration once at startup, register a Watcher on the etcd node, and wait. Whenever configuration is updated, etcd immediately notifies subscribers, ensuring they always have the latest configuration.
etcd Architecture
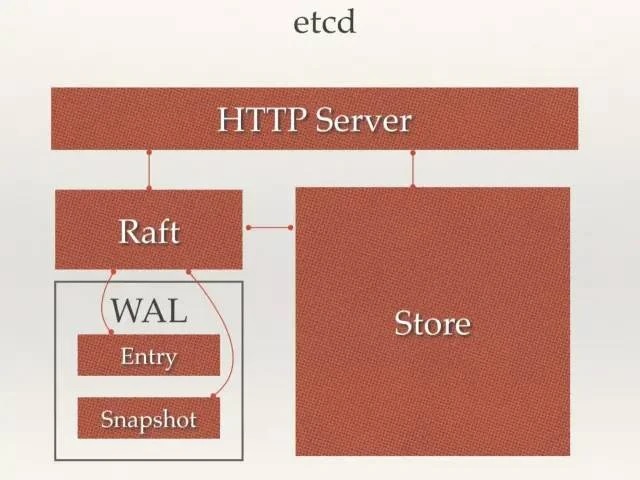
- HTTP Server: Provides the API and data read/write functionality, enabling communication between nodes.
- Raft: Implementation of the Raft strong consistency algorithm.
- Store: Handles various etcd-supported transactional operations, including data indexing, node state changes, monitoring and feedback, event processing and execution. This is the concrete implementation of most API functionality that etcd provides to users.
- WAL: Write Ahead Log — etcd’s data storage method. In addition to keeping all data state and node indexes in memory, etcd uses WAL for persistent storage. All data is logged before being committed.
- Snapshot: State snapshots taken to prevent excessive data accumulation.
- Entry: The specific log content being stored.
etcd Consistency Based on Raft
The Raft protocol is based on the quorum mechanism — the majority-agreement principle. Any change requires confirmation from more than half of the members.
If you’re unfamiliar with Raft, check out http://thesecretlivesofdata.com/raft/.
Election Process
- At initial startup, nodes are in Follower state with an election timeout. If no Leader heartbeat is received within this period, the node initiates an election, switches to Candidate, and sends vote requests to other Follower nodes in the cluster.
- After receiving acceptance votes from more than half the cluster nodes, the node becomes Leader and starts accepting and saving client data while syncing logs to other Follower nodes. If consensus isn’t reached, the Candidate randomly waits (150ms ~ 300ms) before initiating another vote. The Candidate receiving acceptance from more than half the Followers becomes Leader.
- The Leader maintains its position by periodically sending heartbeats to Followers.
- If any Follower doesn’t receive a Leader heartbeat during the election timeout, it also switches to Candidate and initiates an election. Each successful election increments the new Leader’s Term by 1 compared to the previous Leader.
Log Replication
When the Leader receives a log entry (transaction request) from a client, it first appends the log to its local Log, then synchronizes the Entry to other Followers via heartbeat. Followers receive and record the log, then send an ACK to the Leader. When the Leader receives ACKs from a majority (n/2+1) of Followers, the log is marked as committed, appended to local disk, and the client is notified. In the next heartbeat, the Leader notifies all Followers to store the log on their own disks.
Safety
- Safety: A mechanism ensuring every node executes the same sequence. If a Follower becomes unavailable while the current Leader is committing a Log, and later that Follower is elected Leader, the new Leader might overwrite previously committed Logs with new ones, causing nodes to execute different sequences. Safety ensures that the elected Leader always contains previously committed Logs.
- Election Safety: Only one Leader is elected per Term.
- Leader Completeness: Refers to the completeness of the Leader’s log. After a Log is committed in Term1, Leaders in all subsequent Terms must contain that Log. Raft uses Term comparison during the election phase to ensure completeness — a vote is cast if the requesting Candidate’s Term is larger, or if Terms are equal but the Index is larger; otherwise the request is rejected.
WAL (Write Ahead Log)
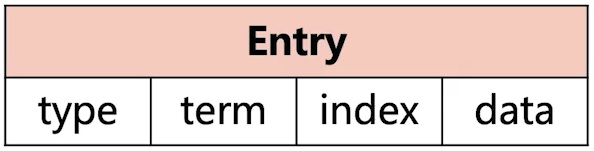
- WAL logs are binary. When parsed, they have the LogEntry data structure shown above.
- The first field is type: 0 means Normal, 1 means ConfChange (etcd configuration change sync, e.g., when a new node joins).
- Term: Each term represents a Leader’s tenure. The term increments by one with each Leader change.
- Index: This strictly ordered incrementing sequence number represents the change sequence.
- Binary data: The entire Raft request object’s protobuf structure is saved.
- Under the etcd source code, there’s a tools/etcd-dump-logs utility that can dump WAL logs to text for viewing, helpful for analyzing the Raft protocol.
- The Raft protocol itself doesn’t care about application data (the data part). Consistency is achieved by syncing WAL logs. Each node applies data received from the Leader to local storage. Raft only cares about log sync status — if local storage has a bug, it could lead to data inconsistency.
Conclusion
I’ve finally gained a foundational understanding of one of Kubernetes’ core components. I’ll continue sharing more core components in upcoming posts.
Feel free to leave a comment on my blog. Your feedback motivates me to keep writing. Thank you for reading, and let’s grow together to become better versions of ourselves.
